

Climate sensitivity is the thing in climate science right now. A part of the climate sensitivity debate is how sensitive climate is to CO2 The arguments seem to be getting more vitriolic and personal as the days past by. It really wasn’t helped by a Daily Mail article. The Daily Mail is a tabloid in the UK.
Whilst the errors in that article are far too numerous to even be bothered with, and the journalist who authored it has done it before, it is interesting to note that the Met Office has started to publish rebuttals with, evidently, more to come. I would personally have ignored it (and him) It seems perfectly reasonable to refer to this particular tabloid as the Daily Fail.
However, it occurred to me, whilst I haven’t access to any amount of supercomputer resources, or a wealth of top-end climate researchers at my fingertips, it must be possible to make a ballpark estimate of climate sensitivity with just publicly available data, a spreadsheet, a cup of coffee, and a little bit of time.
If we want to know how sensitive the climate is, we need to figure out what drives it – ie climate parameter attribution. So, what do we know about climate attribution? Here’s the IPCC’s view,

Essentially, what we have, here, is the range of possible forcings and their quantitative forcing value in W m-2 (a measure of irradiance, Watts per square metre) Here’s the list as a table,
| Min | Max | IPCC | Mean | Diff | % | |
| CO2 | 1.490 | 1.830 | 1.660 | 1.660 | 0.000 | 0.902 |
| CH4 | 0.430 | 0.530 | 0.480 | 0.480 | 0.000 | 0.261 |
| Ozone (Troposheric) | 0.250 | 0.650 | 0.350 | 0.450 | −0.100 | 0.190 |
| Halocarbons | 0.310 | 0.370 | 0.340 | 0.340 | 0.000 | 0.185 |
| N20 | 0.140 | 0.180 | 0.160 | 0.160 | 0.000 | 0.087 |
| Solar Irradiance | 0.060 | 0.300 | 0.120 | 0.180 | −0.060 | 0.065 |
| Surface Albedo (Black Carbon) | 0.000 | 0.200 | 0.100 | 0.100 | 0.000 | 0.054 |
| Water Vapour | 0.020 | 0.120 | 0.070 | 0.070 | 0.000 | 0.038 |
| Contrails | 0.003 | 0.030 | 0.010 | 0.017 | −0.007 | 0.005 |
| Ozone (Stratospheric) | −0.150 | 0.050 | −0.050 | −0.050 | 0.000 | −0.027 |
| Surface Albedo (Land Use) | −0.400 | 0.000 | −0.200 | −0.200 | 0.000 | −0.109 |
| Aerosol (Direct effect) | −0.900 | −0.100 | −0.500 | −0.500 | 0.000 | −0.272 |
| Aerosol (Cloud albedo) | −1.800 | −0.300 | −0.700 | −1.050 | 0.350 | −0.380 |
Here, we note that for the most part, the IPCC has used the arithmetic mean of the forcing range for the actual forcing values; in same cases this isn’t true, and I’ve noted the difference, well, in the ‘Diff’ column. Also, I’ve calculated the percentage of the sum of IPCC forcings each parameter is.
One thing we can take from this (I may comment on the differences between forcing and the arithmetic mean of the forcing range at some later date) is that by one hell of a margin the IPCC state categorically that CO2 is by far the biggest contributor to climate forcing. I was surprised by how much the emphasis was on CO2.
Given that – and please remember this is a cup of coffee, back of a cigarette packet study – I am going to initially assume that the entire climate signal, and therefore climate sensitivity, is down to CO2. I know that’s wrong, and, for sure, there’s going to be some that pick up on it: but here’s the paragraph that says ‘I already know’ Remember we are looking for ballpark figures here.
Given our primary (incorrect, but good enough) assumption, then, let’s get some data. As normal I will be using the HadCrut4 climate data and for CO2 I will be using Earth System Research Laboratory dataset. Honestly, I didn’t really know whether I should be picking insitu CO2 measurements, or flasks; I opted for flasks pretty much on a hunch,

Here you can see that it’s actually a pretty good fit; it seems perfectly reasonable to say that as CO2 increases, so does temperature anomaly. I put a straight line fit through to see what the r2 value was. This value tells us how good the correlation between CO2 and temperature anomaly actually is. If it’s +1 then there is a perfectly positive correlation; if it is -1 then there is a perfectly negative correlation. If it’s zero, then the variables do not correlate whatsoever. So, pretty much, the close you get to either +1, or -1, the better the correlation you’ve got.
Here we get up to 0.635, which, is a worthy value of investigation. However, if you look at the way the dots are arranged, it looks like a curve. A log curve, to be precise. Here’s the finished chart with all the titles, labels, and a log fit curve,

That’s better, but, it doesn’t provide for significantly better fit. The reason is that CO2‘s logarithmic relationship with temperature is much more evident over very long periods of time – lengths of time that are longer than a human lifetime, for sure. I think we’ll stick to the logarithmic fit, even though for the time scales we’re investigating the relationship might as well be linear.
Least linear squares, by a trial and error algorithm, eventually transforms the data we have into the following equation. And this gives us a simple model to which we can figure out climate sensitivity based on what little empirical observation we can get out hands on.

The Sgn function is a requirement of the internal model that Gnumeric uses; it makes it look all the more awkward, but, hey, if someone else wants to reproduce it, it really matters that you tell everyone. Here’s the chart of the idealised CO2 vs Temperature Anomaly curve,

Using this model we can take the difference between 280ppmv and 560ppmv, which are -2.503 and 1.219, respectively, which gives us a climate sensitivity of 3.722oC. 90% of that value – since that’s the extent of the IPCC CO2 forcing – is 3.35oC. In the grand scheme of things, that’s about the middle of the road ball-park figure; neither particularly high, nor particularly low.
One of the most interesting features of this chart is that it implies that most of the (fast) warming has already been done, and that we’re at the beginning of the rather flat section of the curve (we’re currently at ~400ppmv) In other words, the effect of polluting our planet with more CO2 will progressively have less and less of an effect. For instance between 400ppmv and 500ppmv the increase is about another 0.5oC and between 500ppmv and 600ppmv even less coming in at around 0.2oC. And horror story of horror stories, a tripling of CO2 will add a measly 1.2C – which given today’s anomaly of ~0.6oC adds up to ~1.8oC which is still less than the 2oC threshold for dangerous climate change.
In all respects this is likely wrong given far too many simplifications and assumptions; but it is in the ballpark; I suggest that it’s rather too high, given that the period that the data is from contains two very distinct properties. The sharp rise in temperature at the end of the last century, and the hiatus during the 21st century which are going to screw things up. Also, of course, this doesn’t account for any feedbacks or feed-forwards.
There you have it: a back of cigarette packet, cup of coffee, analysis of climate sensitivity. I doubt some British journalists go to as much trouble during their coffee breaks.


 as the direction of the vector and the length of the arrow
as the direction of the vector and the length of the arrow  being the magnitude – ie wind direction, and wind speed respectively. Of course, when one wants to think of wind direction we must think of the complete compass face.
being the magnitude – ie wind direction, and wind speed respectively. Of course, when one wants to think of wind direction we must think of the complete compass face.
 , some people use bold: some people even use bold and italics. I am opting for something simple – I will simply use bold. The reason why
, some people use bold: some people even use bold and italics. I am opting for something simple – I will simply use bold. The reason why 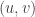 is chosen, is convention in the meteorological literature. If you are trying to convert, for instance, output from a gridded weather model, these parameters will be expressed as
is chosen, is convention in the meteorological literature. If you are trying to convert, for instance, output from a gridded weather model, these parameters will be expressed as  , and direction with
, and direction with  . Well, you could, but, unfortunately, that will be wrong. We have to encode the information into a vector so we can use it as one quantity. If we simply copied the details over, it would be a special class of something called an n-tuple – in this case a pair – which isn’t the same thing as a vector. It’s also the case that I’ve committed a cardinal sin and used
. Well, you could, but, unfortunately, that will be wrong. We have to encode the information into a vector so we can use it as one quantity. If we simply copied the details over, it would be a special class of something called an n-tuple – in this case a pair – which isn’t the same thing as a vector. It’s also the case that I’ve committed a cardinal sin and used  , and direction,
, and direction,  , we compute
, we compute 

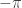 inside the trigonometric functions; this, with a bit of care, keeps the transform the other way, within the bounds of 0..360 degrees; it will always be within this value, even, if, say, you have a direction of 380 degrees (which could happen as the result of some computation) the reverse process will return 20 degrees. It’s rather like adding 3 hours to 11pm: the answer isn’t 14pm, the answer is 2am: that’s just the effect we need.
inside the trigonometric functions; this, with a bit of care, keeps the transform the other way, within the bounds of 0..360 degrees; it will always be within this value, even, if, say, you have a direction of 380 degrees (which could happen as the result of some computation) the reverse process will return 20 degrees. It’s rather like adding 3 hours to 11pm: the answer isn’t 14pm, the answer is 2am: that’s just the effect we need.

 .
.
 is the value we’re interested in,
is the value we’re interested in,  is the gradient which is how steep the line is, and
is the gradient which is how steep the line is, and  is the value where the line will cross the
is the value where the line will cross the 









